Executive Summary
- The basic production process in pro team sports is converting financial expenditure on playing talent into sporting performance
- Any process can be summarised as Resource x Efficiency = Performance
- Sporting efficiency is measured by the wage cost per win (i.e. the win-cost ratio)
- Teams pursuing a “David” strategy seek high sporting performance on a limited financial budget by achieving high levels of sporting efficiency
- Sporting efficiency can be decomposed into two components: (i) transactional efficiency i.e. maximising the quality of playing talent acquired per unit wage cost; and (ii) transformational efficiency i.e. maximising the sporting performance of a given playing squad
- The original Moneyball story was about how the Oakland A’s used data analytics to achieve exceptional levels of transactional efficiency in recruitment
- The “new” Moneyball story is how teams are using data analytics to maximise transformational efficiency
All professional sports teams consist of two operations: (i) the sporting operation which produces the team’s core product, namely, on-the-field sporting performance; and (ii) the business operation tasked with monetarising the sporting performance through a variety of revenue streams, principally matchday receipts, media, sponsorship and merchandising. The basic production process in professional team sports is the conversion of financial expenditure on playing talent into sporting performance. Simply put, pro sports teams are in the business of turning wages into wins.
Any process can be summarised as
RESOURCE x EFFICIENCY = PERFORMANCE
In the case of pro sports teams, the resource (i.e. input) is the financial budget available to spend on playing talent. For the moment to keep things simple, let us assume initially that the resource represents wage expenditure on players. Performance is sporting performance which , again for simplicity, we will assume initially comprises competing in a league with performance measured by wins or league points. The efficiency of any process represents the rate at which input can be converted into output. Sporting efficiency is measured by the rate at which wage expenditure can be converted into wins (or league points). It is conventional to express sporting efficiency as the wage cost per win, often referred to as the win-cost ratio. In leagues with tied games and/or bonus points, sporting efficiency is best measured as the wage cost per point.
The Resource-Efficiency relationship captures the strategic differences between teams. Typically leagues consist of a mix of big-market teams and smaller teams. The big-market teams are usually located in big metropolitan areas and have a history of sporting success. Their fanbases are large and loyal so that these teams are economically powerful, financial Goliaths in sporting terms who are able to afford large player wage budgets which gives them a strategic advantage over the smaller teams. The economically smaller teams with more limited financial budgets can only remain competitive in a financially sustainable way by developing a “David” strategy to achieve high levels of sporting efficiency. Leagues concerned about the competitive dominance of the big-market teams often attempt to restrict the resource differential between teams through measures such as (i) salary caps and other financial restrictions on player wage expenditures; (ii) revenue redistribution through centralised media and sponsorship deals; and (iii) direct controls on the player labour market including centralised player drafts.
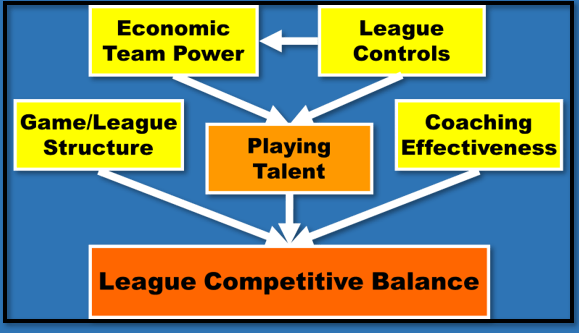
Sporting efficiency can be decomposed into two components: transactional efficiency and transformational efficiency. Transactional efficiency refers to the efficiency with which teams spend their player wage budget to acquire playing talent. Teams with high transactional efficiency maximise the quality of playing talent acquired per unit wage cost. Transformational efficiency refers to the efficiency with which a playing squad is trained and utilised to win sporting contests. Transformational efficiency is all about maximising the sporting performance achieved by a given playing squad. Transactional efficiency is the responsibility of the recruitment department whereas transformational efficiency is the responsibility of the coaching staff and the other sporting support staff. Transactional and transformational efficiency are interdependent. Effective recruitment is not solely about identifying high-quality players undervalued in the market. These players must be high quality in team-specific terms by which I mean, players with the qualities to be able to adapt and perform within the specific training regime and playing style of the team.
Figure 1: Decomposing Sporting Efficiency

In recent years there has been considerable focus on the use of data analytics as a key element in the David strategy of teams seeking to maximise sport efficiency. The original Moneyball story was about how the Oakland A’s used data analytics to achieve exceptional levels of transactional efficiency in recruitment. At the core of the A’s analytics-driven recruitment strategy was their innovative use of On-Base Percentage (OBP) as a key metric to identify undervalued batters. In a study that I published in 2007, I estimated that the A’s were 59.3% more efficient than the MLB average over the period 1998-2007 which represents Billy Beane’s first nine seasons as GM. This calculation was based on the win-cost ratio after allowing for wage inflation.
What I call the “New Moneyball” is the application of data analytics to enhance the transformational efficiency of teams. In this respect, I find it useful to think of playing talent holistically using what I call the 4 A’s – Ability (i.e. technical skills), Athleticism (i.e. physical skills), Attitude (i.e. mental skills) and Awareness (i.e. decision skills). Data analytics is contributing to all of these aspects of playing talent, augmenting the work of coaches, sport scientists, strength and conditioning trainers and sport psychologists.
One final issue – the simplifying assumptions in the measurement of both the cost of playing talent and sporting performance need to be reviewed. As regards the cost of playing talent, there is the complication of how to treat transfer fees particularly given their importance in (association) football. One alternative is that adopted by Tomkins et al, Pay As You Play (GPRF Publishing, 2010) who provided a detailed analysis of what they called “the price of success” in the English Premier League (EPL), 1992 – 2010, using their Transfer Price Index. Their efficiency measure was the transfer cost per league point using the inflation-adjusted transfer value of the playing squad. Another approach is what I would call “the full-cost method” in which acquisition costs are included as well as wage costs. The simplest version of this method is to combine the annual amortisation charge on transfer fees paid with annual wages and salaries. My own preference is to use the wages-only method in analysing what I would call “operating-cost sporting efficiency” and to separately analyse the ”capital-cost sporting efficiency” of transfer fees paid and received.
As regards the measurement of sporting performance, the principal problem again arises primarily in football when the top teams compete in two elite tournaments – their own domestic league and an international tournament. For example, top English teams compete in both the EPL and the UEFA Champions League. Their sporting efficiency should be assessed in terms of their performance in both tournaments. But trying to a create a composite measure of sporting performance in multiple tournaments is difficult and aways open to the charge of arbitrariness. So, just as in the case of the measurement of player costs, I advocate separability i.e. analyse the efficiency of sporting performance in different tournaments separately. Ultimately it comes down to making meaningful comparisons using metrics that are transparent and measured consistently to ensure that we are comparing like with like as much as possible. So, for example, it is much more informative to compare the wage cost per point of the EPL teams competing in the UEFA Champions League with each other and then separately compare the wage cost per point of the other EPL teams.
Other Related Posts