Executive Summary
- There were three key features of the IPL auction values of players in 2023:
- A premium was paid for top Indian talent
- High values were attached to top but more risky overseas talent
- It cost more to buy runs scored than it did to limit runs conceded
- Mumbai Indians were the top batting side in 2023 but ranked poorly on bowling hence the expectation that they will focus on strengthening their bowling resources in the 2024 auction
- This intention has clearly been signalled by the release of a large number of their bowlers and the high-profile trade for the return of Hardik Pandya
- In any auction there is an ever-present danger of the Winner’s Curse – winning the auction by bidding an inflated market value well in excess of the productive value
During my recent visit to the Jio Institute in Mumbai, I undertook some research on the player auction in the Indian Premier League (IPL). I also used the IPL as the context to investigate the topics of player ratings and player valuation with my graduate sport management class. The discussion with my students, several of whom had a very good knowledge of the IPL and individual teams and players, was motivated by Billy Beane’s involvement in the IPL as an advisor to the Rajasthan Royals. In a recent conversation with Billy, he commented that cricket is undergoing its own sabermetrics revolution. So the question I set the students – are there any apparent Moneyball-type inefficiencies in the valuation of players in the IPL player auctions, with a specific focus on last year’s auction? And looking ahead, could we predict the strategies that individual teams might adopt in the 2024 auction to be held in Dubai on 19th December?
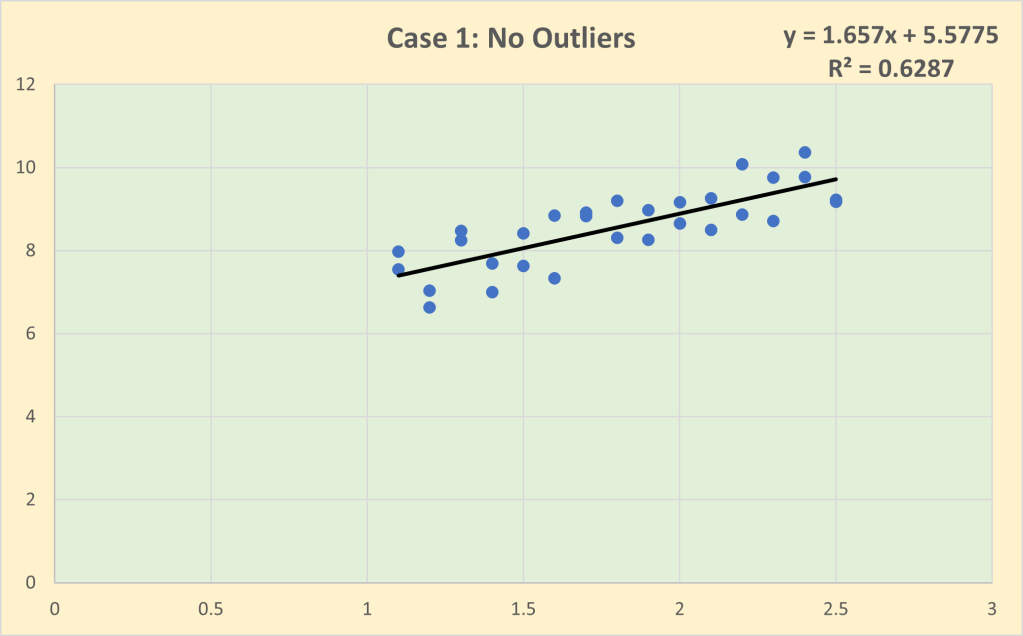
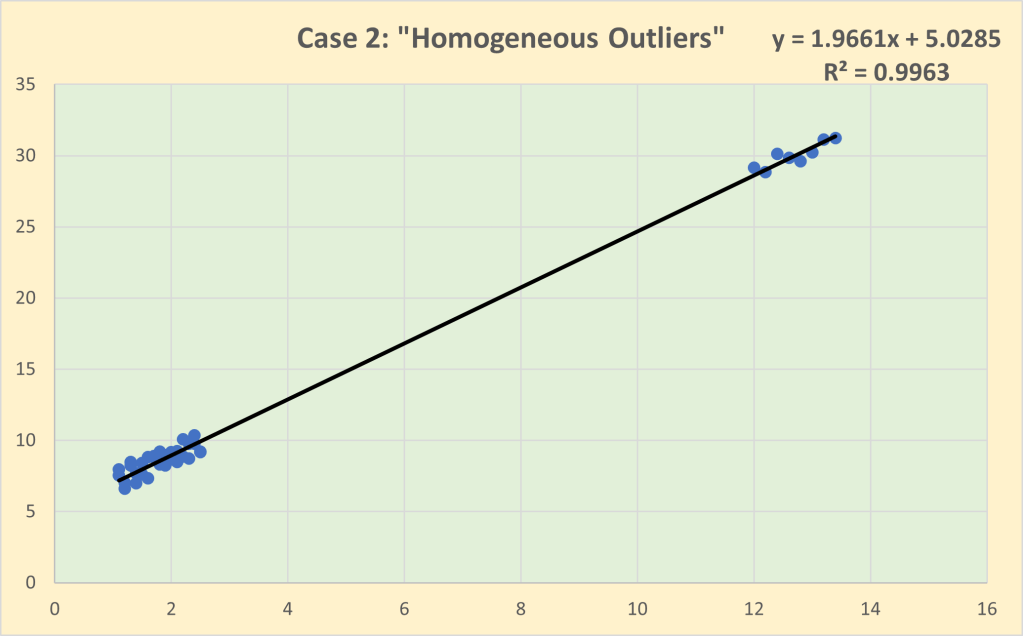
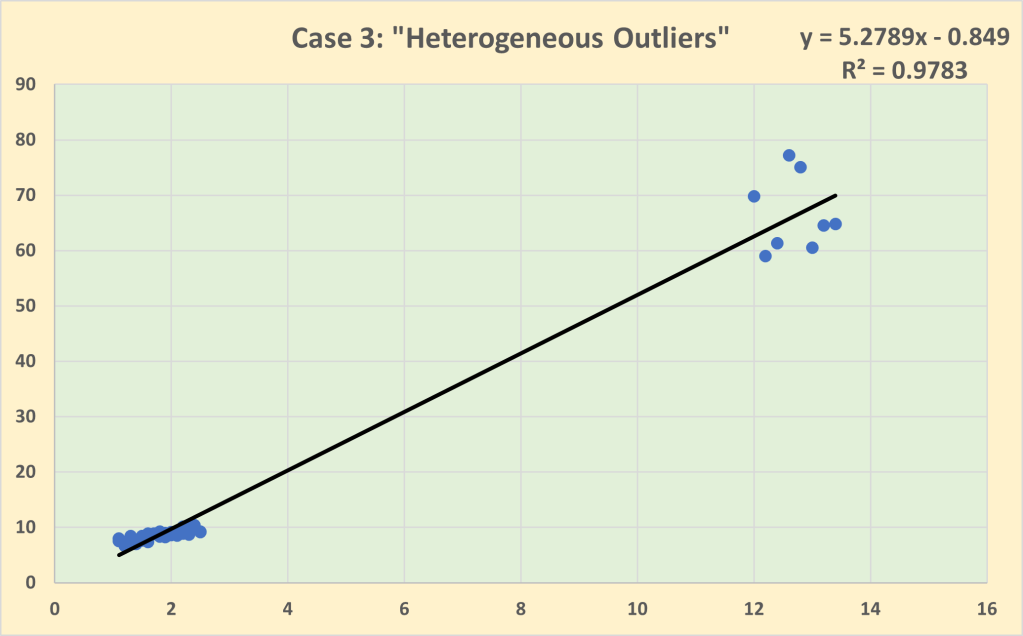
Looking at the 2023 IPL player auction, there appear to be three key features of the player values:
- There is a premium paid for top domestic talent when these players become available
- High values are attached to top overseas talent but they are higher risk
- It costs more to buy runs scored than it does to limit runs conceded
It is no surprise that top Indian players command the highest values – they are experienced and effective in the playing conditions, are big box-office draws, and have high scarcity value. These players are the first on their current team’s retained list and both difficult and expensive to prise them away to another team with a sufficiently lucrative deal for all parties.
As a consequence, teams are forced to focus on the overseas market to find an alternative source for top talent. But this can be a high-risk strategy. Often these players have little or no previous experience in playing in the IPL or even playing in India. Their availability for the whole tournament can be problematic. For example, the IPL overlaps the early part of the English domestic season and top English players are likely to have commitments to the national teams in both test and limited-overs matches. And there is the ever-present risk of injury as the playing schedule extends throughout the whole year. Two of the top valued players in last year’s IPL player auction were Ben Stokes and Harry Brook. Stokes was limited to bowling only one over and had two short innings with the bat before injury ended his IPL season; his obvious priority as captain of the England test team and the inspiration behind the Bazball approach was to get fit for the Ashes series. He has just been released by Chennai Super Kings and has undergone knee surgery in the last few days. Stokes will not be available for the IPL in 2024. Understandably, Harry Brook as an emerging star, commanded one of the highest auction values but his performances in his first season in the IPL were disappointing by his high standards. On my rating system, he ranked only 44th out of the 50 batsmen with 11+ innings but was the 5th highest valued player in the auction. Sunrisers Hyderabad have waived their right to retain his services for the IPL in 2024.
In a number of pro team sports, there is tendency for teams to put a higher value on offensive players who score compared to defensive players who prevent scores being conceded. This is a market inefficiency since a score for has the same weighting as a score against in determining the match outcome. The inefficiency is perhaps more explicable in the invasion-territorial team sports such as the various codes of football since it is more difficult in these sports to separate out the impact of individual player contributions. And, after all, scoring is an observable event whereas defence is about preventing scoring events occurring so there is added uncertainty as to whether or not a score would have been conceded had it not been for a particular defensive action by a player. But this inefficiency is much less explicable in striking-and-fielding team sports such as baseball and cricket where the responsibility for scores conceded can be much more clearly be allocated to individual pitchers/bowlers and fielders. So perhaps a Moneyball-type strategy could be adopted by IPL teams who are weaker in their bowling.
Given that I was based in Mumbai and visiting the Jio Institute which has been established by Reliance Industries who also own the Mumbai Indians franchise, the obvious team to analyse were the Mumbai Indians. I hasten to add that I am not privy to any “inside information” and all of my analysis is based on publicly available data. Table 1 below summarises the batting and bowling performances of the 10 IPL team in 2023.
Table 1: Team Summary Performance, Batting and Bowling, IPL 2023

Note: Runs scored and runs conceded are calculated per ball for all matches (i.e. regular season and end-of-season playoffs). The overall batting and bowling rankings include a number of metrics other than just the scoring and conceding rates.
As can be seen in Table 1, the Mumbai Indians topped the charts in batting but performed relatively poorly in bowling. This suggests that their focus in the coming auction will be on strengthening their bowling. Their intent has clearly been signalled by the release of a large proportion of their bowlers and the high-profile trade for the return of Hardik Pandya.
One final thought as regards the forthcoming IPL player auction. In any auction there is an ever-present danger of the Winner’s Curse – winning the auction by bidding an inflated market value well in excess of the productive value. “Winning the battle, losing the war.” Any bidder in any auction is well advised to have a clear idea of the expected productive value of the future performance of the asset for which they are bidding. In the case of players, it is vital to have a well-grounded estimate of the future value of both the player’s expected incremental contribution on-the-field as well as their image value off-the-field. This should set the upper bound for a team’s bid for their services. As in any acquisition, you are buying the future not the past. Outbid the other teams and you secure the employment contract for the player giving you the rights to the uncertain future performance of the player. Past performance is a guide to possible future performance but you must always factor in the uncertainty inevitably attached to expected future performance.