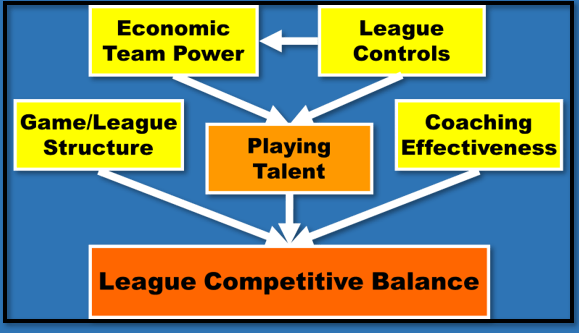
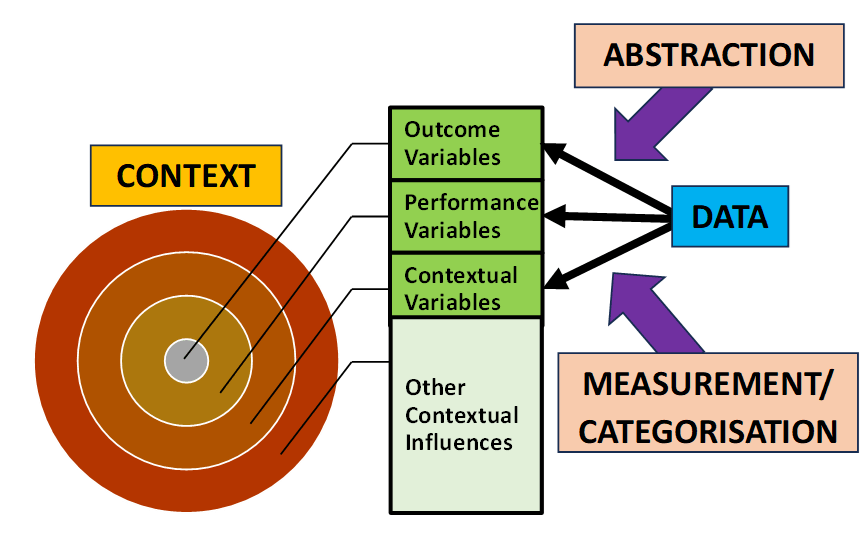
Analytical models are a simplified, purpose-led, data-based representation of a real-world problem situation. In terms of the categorisation of data proposed in the previous post, “Putting Data in Context” (24th Jan 2024), analytical models typical take the form of a multivariate relationship between the process outcome variable and a set of performance and context (i.e. predictor) variables.
Outcome = f(Performance, Context)
In evaluating the estimated models derived from a particular dataset, there are three general criteria to be considered:
- Specification criterion: is the model as simple as possible but still comprehensive in its inclusion of all relevant variables?
- Usability criterion: is the model fit for purpose?
- Diagnostic testing criterion: does the model use the available data effectively?
These criteria are applicable to all estimated analytical models but the specific focus and empirical examples in this series of posts will be linear regression models.
Specification Criterion
Analytical models should only include as predictors the relevant performance and context variables that influence the (target) outcome variable. To keep the model as simple as possible, irrelevant variables with no predictive power should be excluded. In the case of linear regression models the adjusted R2 (i.e. adjusted for the number of variables and observations) is the most useful statistic for comparing the goodness of fit across linear regression models with different numbers of predictors. Maximising the adjusted R2 is equivalent to minimising the standard error of the regression and yields the model specification rule of retaining all predictors with (absolute) t-statistics > 1.
Usability Criterion
The purpose of an analytical model is to provide an evidential basis for developing an intervention strategy to improve process outcomes. There are three general requirements for a usable analytical model:
- All systematic influences on process outcomes are included
- Model goodness of fit is maximised
- One or more predictor variables are controllable, that is, (i) causally linked to the process outcome; (ii) a potential target for managerial intervention; and (iii) with a sufficiently large effect size
Diagnostic Testing Criterion
A linear regression model takes the following general form:
Outcome = f(Performance, Context) + Stochastic Error
There are two components: (i) the structural model, f(.), that seeks to capture the systematic variation in the process outcome associated with the variation in the performance and context variables; and (ii) the stochastic error that represents the non-systematic variation in the process outcome. The stochastic error captures the myriad of “local” context-specific influences that impact on the individual observations but whose effects are not generalisable in any systematic way across all the observations in the dataset.
Regression analysis, like all analytical models, assumes that (i) the structural model is well specified; and (ii) the stochastic error is random (which, in formal statistical terms, requires that the errors are identically and independently distributed). Diagnostic testing is the process of checking that these two assumptions hold true for any estimated analytical model. To use the signal-noise analogy from physics, data analytics can be seen as a signal-extraction process in which the objective is to separate the systematic information (i.e. signal) from the non-systematic information (i.e. noise). Diagnostic testing involves ensuring that all of the signal has been extracted and that the remaining information is random noise.
A Checklist of Possible Diagnostic Problems
There are three broad types of diagnostic problems:
- Structural problems: these are potential mis-specification problems with the structural component of the analytical model and include wrong functional form, missing relevant variables, incorrect dynamics in time-series models, and structural instability (i.e. the estimated parameters are unstable across subsets of the data)
- Stochastic error problems: the stochastic error is not well behaved and is non-independently and/or non-identically distributed
- Informational problems: the information structure of the dataset is characterised by heterogeneity (i.e. outliers and/or clusters) and/or communality
Informational problems should be identified and resolved during the exploratory data analysis before estimating the analytical model. Diagnostic testing focuses on structural and stochastic error problems as part of the evaluation of estimated models. Within the diagnostic testing process, it is strongly recommended that priority is given to structural problems. Ultimately, as discussed below, diagnostic testing involves the analysis of the residuals of the estimated analytical model. Diagnostic testing is the search for patterns in the residuals. It is a matter of interpretation as to whether any patterns in the residuals are due to structural problems or stochastic error problems. But the solutions are quite different. Structural problems require that the structural component of the analytical model is revised whereas stochastic error problems require a different estimation method to be used. However, the residuals can only be “unbiased” estimates of the stochastic error if and only if the structural component is well specified. It comes down to mindset. If you have a “Master of the Universe” mindset and believe that the analytical model is well specified, then, from that perspective, any patterns in the residuals are a stochastic error problem requiring the use of more sophisticated estimation techniques. This is the traditional approach in econometrics by those wedded to the belief in the infallibility of mainstream economic theory and confident that theory-based models are well specified. In contrast, practitioners, if they are to be effective in achieving better outcomes, require a much greater degree of humility in the face of an uncertain world, recognising that analytical models are always fallible. Interpreting patterns in residuals as evidence of structural mis-specification is, in my experience, much more likely to lead to better, fit-for-purpose models.
Diagnostic Testing as Residual Analysis
Diagnostic testing largely involves the analysis of the residuals of the estimated analytical model.
Residual = Actual Outcome – Predicted Outcome
Essentially diagnostic testing is the search for patterns in the residuals. The most common types of patterns in residuals when ordered by size or time are correlations between successive residuals (i.e. spatial or serial correlation) and changes in their degree of dispersion (known as “heteroskedasticity”). There are three principal methods for detecting systematic variation in residuals:
- Residual plots – visualisations of the bivariate relationships between the residuals and the outcome and predictor variables
- Diagnostic test statistics – formal hypothesis testing of the existence of systematic variation in the residuals
- Auxiliary regressions – the estimation of supplementary regression models in which as the outcome variable is the original (or transformed) residuals from the initial regression model
In subsequent posts I will review the use of residual analysis in both cross-sectional models (Part 2) and time-series models (Part 3). I will also consider the overfitting problem (Part 4) and structural instability (Part 5).
Other Related Posts