Executive Summary
- Financial determinism in professional team sports refers to those leagues in which sporting performance is largely determined by expenditure on playing talent
- Financial determinism creates the “shooting-star” phenomenon – a small group of ”stars”, big-market teams with the high wage costs and high sporting performance, and a large “tail” of smaller-market teams with lower wage costs and lower sporting performance
- There is a very high degree of financial determinism in the English Premier League
- Achieving high sporting efficiency is critical for small-market teams with limited wage budgets seeking to avoid relegation
Financial determinism in professional team sports refers to those leagues in which sporting performance is largely determined by expenditure on playing talent. It is the sporting “law of gravity”. Financial determinism implies a strong win-wage relationship with league outcomes highly correlated with wage costs so that those teams with the biggest markets and the greatest economic power (i.e. the biggest “wallets”) to be able to afford the best players tend to win. Financial determinism creates what can be called the “shooting-star” phenomenon shown in Figure 1. The “stars” are the sporting elite in any league, the big-market teams with the high wage costs and high sporting performance. The rest of the league constitutes the “tail”, the smaller-market teams with lower wage costs and lower sporting performance. Some small-market teams can temporarily defy the law of gravity by achieving high sporting efficiency. The classic example of this is the Moneyball story in Major League Baseball where the Oakland Athletics used data analytics to identify undervalued playing talent. And, of course, there are the bigger market teams who spend big but do so inefficiently and perform well below expectation.

Figure 1: The Shooting-Star Phenomenon
A fundamental proposition in sports economics is that uncertainty of outcome is a necessary condition for viable professional sports leagues. This is the notion that the essential characteristic of sport is the excitement of unscripted drama where the outcome is determined by the contest and is not scripted in advance. Uncertainty of outcome requires that teams in any league are relatively equally matched in their economic power with similar revenues and similar access to financial capital. Unequal distribution of economic power across teams leads to financial determinism. The most common causes of disparities in economic power between teams are location (i.e. teams based in large metropolitan areas often have much bigger fanbases and, consequently, can generate much higher revenues) and ownership wealth (i.e. teams with rich owners who are driven by sporting glory rather than profit and will spend whatever it takes to win). To prevent financial determinism, leagues have used a number of regulatory mechanisms to maintain competitive balance including revenue sharing, salary caps and player drafts.
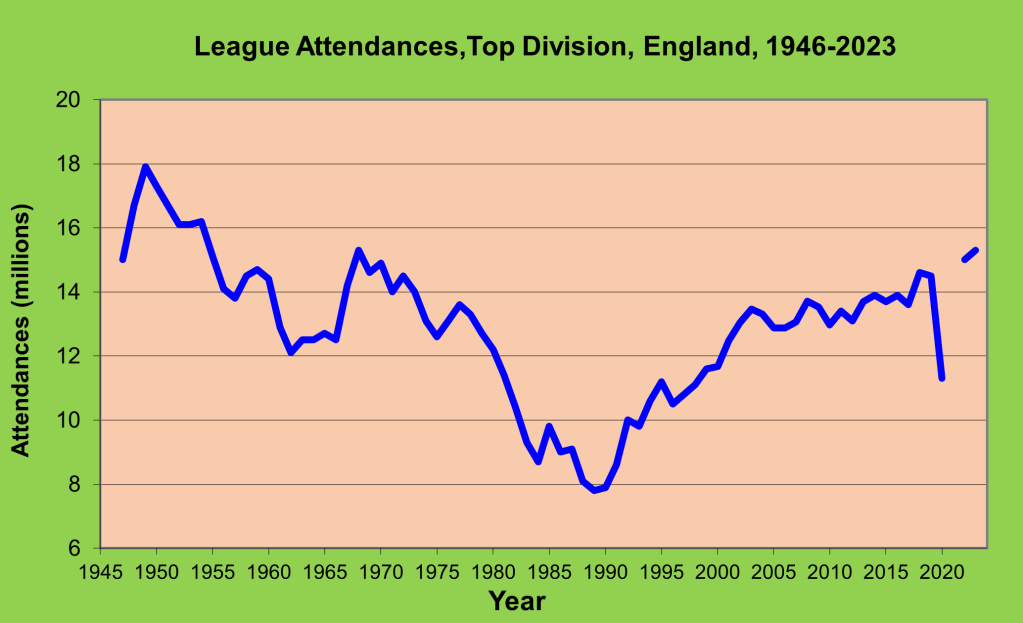
Is the English Premier League subject to financial determinism and the shooting-star phenomenon? To answer this question I have tracked wage costs reported in club accounts from 1995/96 onwards when the English Premier League adopted its current structure of 20 teams and 380 games with three teams relegated. Clubs are still in the process of reporting their 2023 accounts so that the analysis concludes with season 2021/22. Since the analysis covers 27 seasons, wage costs need to be standardised to allow for wage inflation. I have used average wage costs each season to deflate wage costs to 1995/96 levels. Very roughly, £10m wage costs in 1996/97 equates to £200m wage costs in 2021/22. Sporting performance has been measured by league points based on match outcomes; any point deductions for breach of league regulations have been excluded. (Middlesbrough were deducted 3 points in 1996/97 for failing to fulfil a scheduled fixture and Portsmouth were deducted 9 points in 2009/10 for going into administration.) Figure 2 shows the scatterplot of league points and standardised wage costs. The two groupings, the big-spending stars and the lower-spending tail, are very obvious. The tail is very dense and contains most of the observations (73.9% of the clubs had standardised wage costs under £10m). The stars are fewer in number and more dispersed with 10 instances of clubs having standardised wage costs in excess of £20m (which equates to over £400m in 2021/22). The correlation between standardised wage costs and league points is 0.793 which implies that over the 27 seasons, 62.8% of the variation in league performance can be explained by the variation in wage costs. In other words, there is a very high degree of financial determinism in the English Premier League.
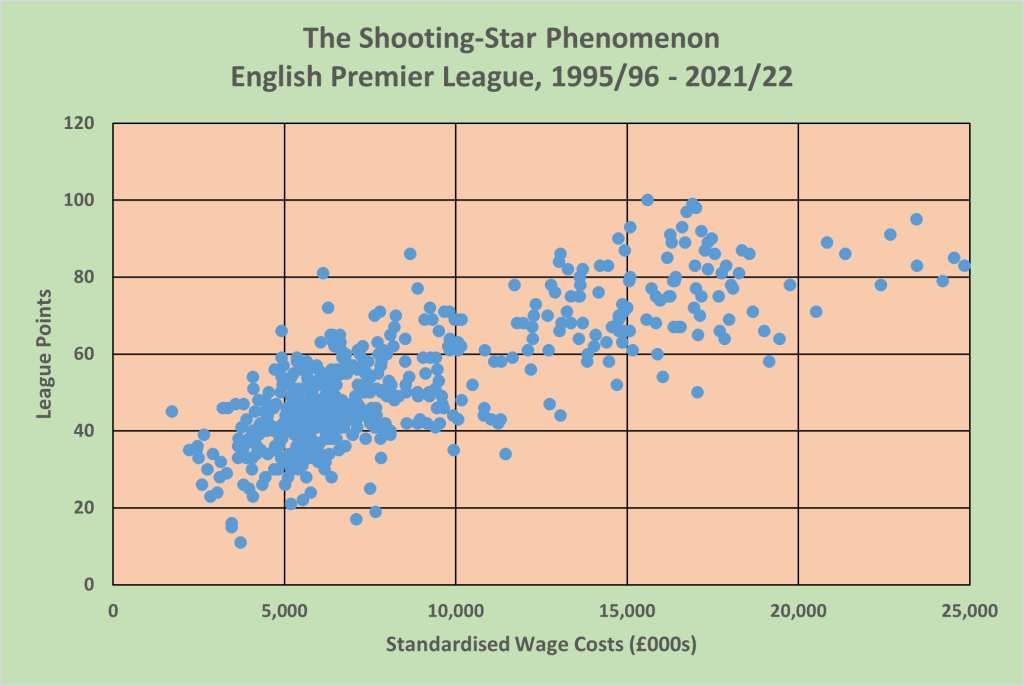
Figure 2: The Shooting-Star Phenomenon in the English Premier League
Season 2021/22 is very typical as regards the degree of financial determinism in the English Premier League as shown in Figure 3. The correlation between wage costs and league points is 0.793 which implies that 61.2% of the variation in league performance can be explained by the variation in wage costs. The linear trendline acts as a performance benchmark – the average efficient outcome for any given level of wage costs – and thus identifies above-average efficient (“above the line”) outcomes and below-average efficient, “below the line” outcomes. At the top end, Manchester City, the champions with 93 points, a single point ahead of Liverpool, were outspent by both Manchester United and Liverpool. Manchester United were highly inefficient gaining only 58 points but with wage costs of £408m. By comparison, West Ham United gained 56 points with wage costs of £136m.

Figure 3: Win-Wage Relationship in English Premier League, 2021/22
As regards relegation, all three relegated teams – Norwich City, Watford and Burnley – lie below the average-efficiency line. In the cases of both Burnley and Watford their final league positions matched their wage rank – their sporting efficiency was not good enough to offset their resource disadvantage. In contrast, Norwich City allocated enough resource to avoid relegation – their wage costs of £117m ranked 15th – but they were highly inefficient. Of the lower spending teams, the two most efficient teams were Brentford and Brighton and Hove Albion who both finished safely in mid-table but ranked 20th and 16th, respectively, in wage costs. In a future post, I will analyse the determinants of sporting efficiency in more detail.
Read other Related Posts